Learnings From Two Years of Kubernetes in Production

Almost two years back, we took the decision to leave behind our Ansible based configuration management setup for deploying applications on EC2 and move towards containerisation and orchestration of applications using Kubernetes. We have migrated most of our infrastructure to Kubernetes. It was a big undertaking and had its own challenges — from technical challenges of running a hybrid infrastructure until most of the migration is done to training the entire team on a completely new paradigm of operations to name a few.
In this post, we would like to reflect on our experience and share our learning from this journey with you, to help you make better decisions and increase your chances of success.
Be clear about your reason to migrate to Kubernetes
All that serverless and containers thing is nice. If you are starting a new business and building everything from scratch, by all means go ahead and deploy your applications using containers and orchestrate them using Kubernetes if you have the bandwidth (or may be not, read on) and the technical skills to configure and operate Kubernetes as well as deploy applications on Kubernetes.
Even if you offload operating Kubernetes to a managed Kubernetes service such as EKS, GKE or AKS, deploying and operating applications on Kubernetes properly also has a learning curve. Your development team should be up for the challenge. A lot of benefits can only be realised if your team follows the DevOps philosophy. If you have central sysadmin teams writing manifests for applications developed by other teams, we personally see lesser benefit of Kubernetes from the perspective of DevOps. Of course, there are numerous other benefits that you can choose Kubernetes for, for example cost, faster experimentation, faster auto-scaling, resilience, etc.
If you are already deploying on cloud VMs or perhaps another PaaS, why are you really considering migrating to Kubernetes from your existing infrastructure? Are you confident that Kubernetes is the only way to solve your problems? You must be clear about your motivations as migrating an existing infrastructure to Kubernetes is a big undertaking.
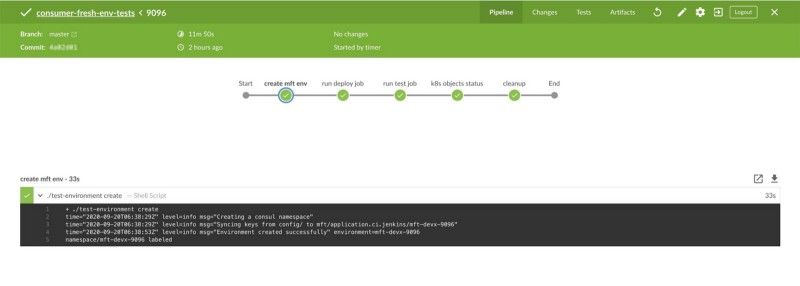
We made some mistakes on this front. Our primary reason to migrate to Kubernetes was to build a continuous integration infrastructure that could assist us with rapid re-architecture of our microservices in which a lot of architecture debt had crept in over the years. Most new features required touching multiple code bases and hence, development and testing all of them together would slow us down. We felt the need to be able to provision an integrated environment for every developer and every change to assist with faster development and testing cycles without coordinating who gets the “shared stage environment”.
micro-services micro-services
Great! What did it take us to build all of this? It took us almost 1.5 years. So was it worth it?
It took us almost 1.5 years to stabilize this complex CI setup by building additional tooling, telemetry and redoing how every application is deployed. For the sake of dev/prod parity, we had to deploy all these micro-services to production as well or else just the drift between the infrastructure and deployment setup will make the applications hard to reason about for developers and would have made ops for developers a nightmare.
We have mixed feelings about this topic. In retrospect, we think we made our problem of solving for continuous integration worse because the complexity of pushing all microservices to production for dev/prod parity made the challenge of achieving faster CI builds a lot more complex and difficult. Before Kubernetes, we were using Ansible with Hashicorp Consul and Vault for infrastructure provisioning, configuration management and deployments. Was it slow? Yes, absolutely. But we think we could have introduced service discovery with Consul and optimized Ansible deployments a bit to get close enough to our goal in a reasonably shorter time.
Should we have migrated to Kubernetes? Yes, absolutely. There are several benefits of using Kubernetes — service-discovery, better cost management, resilience, governance, abstraction over infrastructure of cloud infrastructure to name a few. We are reaping all these benefits today as well. But that was not our primary goal when we started and the self-imposed pressure and pain of delivering the way we did was perhaps unnecessary.
One big learning for us was we could have taken a different and lesser resistant path to adopting Kubernetes. We were just bought into Kubernetes as the only solution that we didn’t even care to evaluate other options.
We will see in this blog post that migration and operations on Kubernetes are not the same as deploying on cloud VMs or bare metals. There is a learning curve for your cloud engineering and development teams. It might be worth it for your team to go through it. But do you need to do that now is the question. You must try to answer that clearly.
Out-of-the-box Kubernetes is almost never enough for anyone
A lot of people get confused with Kubernetes as a PaaS solution — it’s not a PaaS solution. It is a platform to build PaaS solutions. OpenShift is one such example.
Out-of-the-box Kubernetes is never enough, for almost anyone. It’s a great playground to learn and explore. But you are most likely going to need more infrastructural components on top and tie them well together as a solution for applications to make it more meaningful for your developers. Often this bundle of Kubernetes with additional infrastructural components and policies is called Internal Kubernetes Platform. This is as an extremely useful paradigm and there are several ways to extend Kubernetes.
Metrics, logs, service discovery, distributed tracing, configuration and secret management, CI/CD, local development experience, auto-scaling on custom metrics are all things to take care of and make a decision. These are only some of the things that we are calling out. There are definitely more decisions to make and more infrastructure to set up. An important area is how are your developers going to work with Kubernetes resources and manifests — more on this later in this blog post.
Here are some of our decisions and rationale.
Metrics
We finalized on Prometheus. Prometheus is almost a defacto metrics infrastructure today. CNCF and Kubernetes love it very much. It works really well within the Grafana ecosystem. And we love Grafana! Our only problem was that we were using InfluxDB. We have decided to migrate away from InfluxDB and totally commit to Prometheus.
Logs
Logs have always been a big problem for us. We have struggled to create a stable logging platform using ELK. We find ELK full of features that are not realistically used by our team. Those features come at a cost. Also, we think there are inherent challenges in using Elasticsearch for logs, making it an expensive solution for logs. We finalized on Loki by Grafana. It’s simple. It has necessary features for our team’s needs. It’s extremely cost-effective. But most importantly, it has a superior UX owing to it’s query language being very similar to PromQL. Also, it works well with Grafana. So that brings the entire metrics monitoring and logging experience together in one user interface.
Configuration and Secret Management
You will find most articles use configmap and secret objects in Kubernetes. Our learning is that it can get you started but we found it barely enough for our use-cases. Using configmap with existing services comes at a certain cost. Configmap can be mounted into pods in a certain way — using environment variables is the most common way. If you have a ton of legacy microservices that read configuration from files rendered by a configuration management tool such as Puppet, Chef or Ansible, you will have to redo configuration handling in all your code bases to now read from environment variables. We didn’t find enough reason to do this where it made sense. Also, a change in configuration or secret means that you will have to redeploy your deployment by patching it. This would be additional imperative orchestration of kubectl commands.
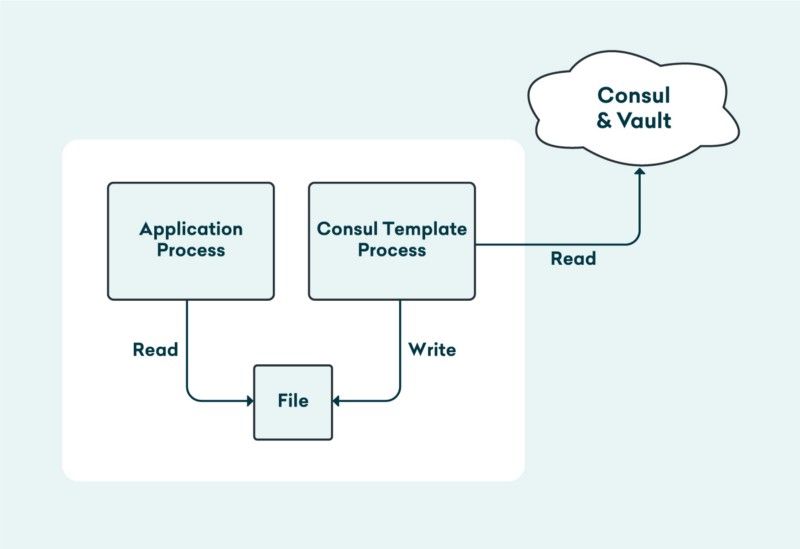
To avoid all this, we decided to use Consul, Vault and Consul Template for configuration management. We run Consul Template as an init container today and plan to run it as a side car in pods so that it can watch for configuration changes in Consul and refresh expiring secrets from Vault and gracefully reload application processes.
CI/CD
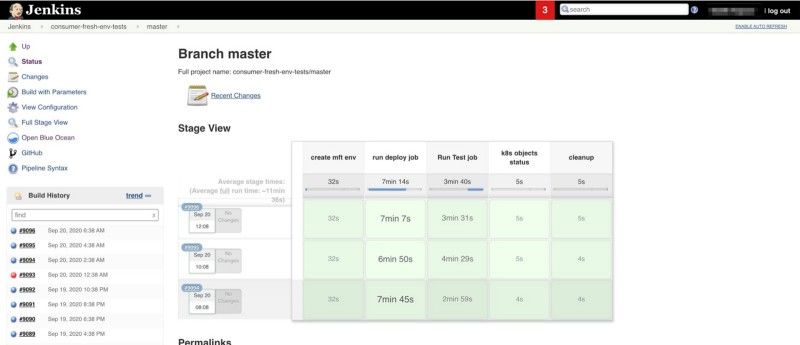
We were using Jenkins before migrating to Kubernetes. After migrating to Kubernetes, we decided to stick to Jenkins. Our experience so far has been that Jenkins is not the best solution for working with cloud-native infrastructure. We found ourselves doing a lot of plumbing using Python, Bash, Docker and scripted/declarative Jenkins pipelines to make it all work. Building and maintaining these tools and pipelines started to feel expensive. We are right now exploring Tekton and Argo Workflows as our new CI/CD platform. There are more options you can explore in the CI/CD landscape such as Jenkins X, Screwdriver, Keptn, etc.
Development Experience
There are a number of ways to use Kubernetes in your development workflow. We mostly zeroed down to two options — Telepresence.io and Skaffold. Skaffold is capable of watching your local changes and constantly deploying them to your Kubernetes cluster. Telepresence, on the other hand, allows you to run a service locally while setting up a transparent network proxy with the Kubernetes cluster so that your local service can communicate with other services in Kubernetes as if it was deployed in the cluster. It is a matter of personal opinions and preferences. It has been hard to decide on one tool. We are mostly experimenting with Telepresence right now but we have not abandoned the possibility of Skaffold being a better tooling for us. Only time will tell what we decide to use, or perhaps we use both. There are other solutions as well such as Draft that deserve a mention.
Distributed Tracing
We are not doing distributed tracing just yet. However, we plan to invest into that area real soon. Like with logging, our desire is to have distributed tracing be available next to metrics and logging in Grafana to deliver a more integrated observability experience to our development teams.
Application Packaging, Deployment and Tooling
An important aspect of Kubernetes is to think about how developers are going to interact with the cluster and deploy their workloads. We wanted to keep things simple and easy to scale. We are converging towards Kustomize, Skaffold along with a few home-grown CRDs as the way for developers to deploy and manage applications. Having said that, any team is free to use whatever tools they would like to use to interact with the cluster as long as they are open-source and built on open standards.
Operating a Kubernetes cluster is hard
We mostly operate out of the Singapore region on AWS. At the time we started our journey with Kubernetes, EKS was not available as a service in the Singapore region. So we had to set up our own Kubernetes cluster on EC2 using kops.
Setting up a basic cluster is perhaps not as difficult. We were able to get up our first cluster running within a week. Most issues happen when you start deploying your workloads. From tuning cluster autoscaler to provisioning resources at the right time to configuring the network correctly for the right performance, you have to do research and configure it all yourself. Defaults don’t work most of the time (or at least they didn’t work for us back then) for production.
Our learning
You have to still think about upgrades
Kubernetes is so complex that even if you are using a managed service, upgrades are not going to be straight forward.
Even when using a managed Kubernetes service, invest early in infrastructure-as-code setup to make disaster recovery and upgrade process relatively less painful in the future and be able to recover fast in face of disasters.
You can make an attempt to push towards GitOps if you will. If you can’t do that, reducing manual steps to a bare minimum is a great start. We use a combination of eksctl, terraform and our cluster configuration manifests (including manifests for platform services) to set up what we call the “Grofers Kubernetes Platform”. To make the setup and deployment process simpler and repeatable, we have built an automated pipeline to set up new clusters and deploy changes to existing ones.
Resource Requests and Limits
After we started migrating, we observed a lot of performance and functional issues in our cluster due to incorrect configuration. One of the effects of that was adding a lot of buffers in resource requests and limits to eliminate resource constraints as a possibility for performance degradation.
One of the first observations was pod evictions due to memory constraints on nodes. The reason for this was disproportionately high resource limits as compared to their resource requests. With surge in traffic, increase in memory consumption could lead to memory saturation on nodes, further leading to pod eviction.
Our learning
This does not apply in case of non-production environments (such as development, staging and CI). These environments don’t get any spike in traffic. Theoretically you can run infinite containers if you set CPU requests to zero and set a high enough CPU limit for your containers. If your containers start utilizing a lot of CPU, they will get throttled. You can do the same with memory requests and limits as well. However, the behaviour of reaching memory limits is different than that of CPU. If you utilize more than the set memory limit, your containers get OOM killed and they restart. If your memory limit is abnormally high (let’s say higher than the node’s capacity), you can keep using memory but eventually the scheduler will start evicting pods when the node runs out of available memory.
In non-production environments, we safely over commit resources as much as possible by keeping resource requests extremely low and limits extremely high. The limiting factor in this case is memory i.e. no matter how low the memory request is and how high the memory limit is, pod eviction is a function of sum of memory utilized by all containers scheduled on a node.
Security & Governance
Kubernetes is meant to unlock the cloud platform for developers, make them more independent and push the DevOps culture. Opening up the platform to developers, reducing intervention by cloud engineering teams (or sysadmins) and making development teams independent should be one of the important goals.
Sometimes this independence could pose severe risks. For example, using the LoadBalancer type service in EKS provisions a public-network facing ELB by default. Adding a certain annotation would ensure that an internal ELB is provisioned.We made some of these mistakes early on.
Open Policy Agent
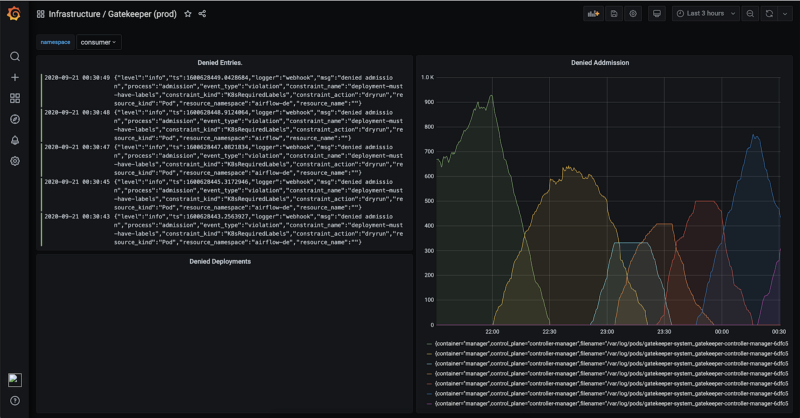
Deploying Open Policy Agent to build the right controls helped automate the entire change management process and build the right safety nets for our developers. With Open Policy Agent, we can restrict scenarios like one just mentioned before — it is possible to restrict service objects from getting created unless the right annotation is present so that developers don’t accidentally create public ELBs.
Cost
We saw massive cost benefits after our migration. However, not all the benefits came immediately.
Note:
Better Resource Capacity Utilisation
This was the most obvious one. Our infrastructure today has far less compute, memory and storage provisioned than we had before. Apart from better capacity utilisation due to better packing of containers/processes, we were able to better utilise our shared services such as processes for observability (metrics, logs) than before.
However, initially we had an enormous amount of wastage of resources while we were migrating. Owing to our inability to tune our self-managed Kubernetes cluster the right way which led to a ton of performance issues, we ended up requesting a lot of resources in our pods as buffer and more like insurance to reduce chances of outages or performance issues due to lack of compute or memory.
High infrastructure cost due to large resource buffers was a big problem. We were not really able to realise any benefits of capacity utilisation due to Kubernetes that we should have. It was after migrating to EKS and observing the stability it brought helped us become more confident, which helped us take the necessary steps to correct resource requests and bring down resource wastage drastically.
Spot
Using spot instances with Kubernetes is a lot easier than using spot instances with vanilla VMs. With VMs, you can manage spot instances yourself which might have some complexity of ensuring a proper uptime for your applications or use a service like SpotInst. The same applies to Kubernetes as well but the resource efficiency brought in by Kubernetes can leave you enough room for keeping some buffer so that even if a few instances in your cluster get interrupted, the containers scheduled on them can be quickly rescheduled elsewhere. There are a few options for efficiently managing spot interruptions.
Spot instances helped us get massive savings. Today, our entire stage Kubernetes cluster runs on spot instances and 99% of our production Kubernetes cluster is covered by reserved instances, savings plan and spot instances.
The next step of optimisation for us is how we can run our entire production cluster on spot instances. More on this topic in another blog post.
ELB Consolidation
We used Ingress to consolidate ELBs in our stage environment and reduce the fixed costs of ELBs drastically. To avoid this from becoming a cause of dev/prod disparity in code, we decided to implement a controller that would mutate LoadBalancer type services to NodePort type services along with an ingress object in our stage cluster.
Migration to Nginx ingress was relatively simple for us and didn’t require a lot of changes because of our controller approach. More savings can come if we use ingress in production as well. It’s not a simple change. Several considerations have to go in configuring ingress for production the right way and needs to be looked at from the perspective of security and API management as well. This is an area we intend to work in the near future.
Increased Cross-AZ Data Transfer
While we saved a lot on infrastructure spend, there is an area of infrastructure where the costs increase — cross-AZ data transfer.
Pods can be provisioned on any node. Even if you control how pods are spread in your cluster, there is no easy way to control how services discover each other in a way that a pod of one service talks to the pod of another service in the same AZ to reduce cross-AZ data transfer.
After a lot of research and conversations with peers in other companies, we learned that something like this can be achieved by introducing a service mesh to control how traffic from a pod is routed to the destination pod. We were not ready to take the complexity of operating a service mesh ourselves just for the benefit of saving the cost of cross-AZ data transfer.
CRDs, Operators & Controllers — A Step Towards Simplified Ops & A More Integrated Experience
Every organisation has its own workflows and operational challenges. We have ours too.
In our two years of journey with Kubernetes, we learned that Kubernetes is great but it’s better when you are using its features such as controllers, operators and CRDs to simplify daily operations and provide a more integrated experience to your developers.
We have started investing in a bunch of controllers and CRDs. For instance, LoadBalancer service type to ingress conversion is a controller operation. Similarly, we use controllers to automatically create CNAME records in our DNS provider whenever a new service is deployed. These are a few examples. We have 5 other separate use-cases where we are relying on our internal controller to simplify daily operations and reduce toil.
We have also built a few CRDs. One of them is widely used today to generate monitoring dashboards on Grafana by declaratively specifying what monitoring dashboards should be constructed with. This makes it possible for developers to check-in their monitoring dashboards next to their application code base and deploy everything using the same workflow — kubectl apply -f . .
We are seeing the benefits of controllers and CRDs massively. As we work closely with our cloud vendor AWS to simplify cluster infrastructure operations, we free ourselves up to focus more on building “the Grofers Kubernetes platform” which is architected to support our development teams in the best way possible.
Interested in infrastructure engineering? Did you know we are hiring?
If this kind of work interests you, feel free to directly reach out to me on LinkedIn, Twitter or just drop me an email.

Vaidik Kapoor is the VP Engineering (DevOps) at Grofers.
Thanks for reading Lambda.
Say hello on Twitter or follow us on LinkedIn.
We’re hiring!
We are hiring across various roles! If you are interested in exploring working at Grofers, we’d love to hear from you. You can either apply on LinkedIn or directly reach out to the author on Twitter or LinkedIn.