The extent of GitOps

I have often thought about what extent of Infrastructure as Code and GitOps is relevant for a company. And I am probably not the only one. Many people in the DevOps, platform engineering and SRE space would also have thought of this question. What should be managed the GitOps way? What's the extent of it?
While the ideal answer is everything is managed via code and operated via the GitOps way, the right answer is that it depends on the situation of your company. The right answer is rooted in the cost (manpower cost, infrastructure cost and most importantly opportunity cost) of moving existing infrastructure and operations to the new way vs the benefits of such changes. Usually, the cost is high.
Revisiting GitOps at DevOps Days London
While attending DevOps Days London, this question came up again in an open spaces discussion on GitOps with Kubernetes. Specifically, the interesting part was the discussion around how some teams have automated the process to commit the number of pod replicas for a deployment/replicaset when an auto-scaling event happens for a deployment in Kubernetes. I have thought about this before while implementing GitOps so I had some opinions on the topic, but it was also interesting to see how others see and solve this challenge, and their extent of implementing GitOps. In the discussion, we tried to go deeper into this but only scratched the surface due to lack of time and other discussion items.
So, through this article, I am going to put my thoughts together on the extent of implementing GitOps and hope to learn what the community thinks about it.
Why GitOps?
First question - why GitOps? I am not going to cover this in detail. In short, GitOps enables teams to practice Continuous Delivery for the entire stack, i.e. from applications to configuration to infrastructure. Why is that important? Because a product or service is built up of all those things.
How does GitOps help with CI/CD? Git is a cornerstone tool for practising CI/CD because of its many benefits:
- Benefits of a Git-based workflow:
- Enables collaboration
- Workflows similar to shipping software changes
- Code reviews
- Continuous integration using automation and pipelines
- Audit log and change history help understand what changed
- Free backups work as a great Disaster Recovery mechanism
- A single source of truth helps ensure that engineers can easily reconcile their code and the system
- Additional benefits of Infrastructure as Code (IaC) provide an easy repeatable setup of infrastructure
Hence, bringing in Git to manage the infrastructure and its operations declaratively enables teams to follow similar release workflows for managing infrastructure operations as for applications.
To what limit should we adopt GitOps?
Like some of the teams in the open space discussion at DevOps Days London, one of the teams I used to manage in the past had also gone down the path of replicating infrastructure state (like replica count of a Kubernetes deployment or number of instances in an auto-scaling group).
Git was primarily built for humans to collaborate on shared codebases. Sure, it can be used to store any changes (like a database), but you can use anything for anything by that logic (like bash for building a web service, or S3 is an application database). The benefit of bringing infrastructure configuration in a code repository is that (platform and product) engineers can collaboratively build the infrastructure the same way they have collaborated on shared codebases to build software. So in my opinion, that's the main value of GitOps - collaboration between teams.
But soon after we started on the path to replicating the infrastructure state into a Git repository, we realised that replicating the infrastructure state into a Git repository is complex and perhaps not worth it. Some of the complexities we faced when we were trying this approach (one of these was also discussed at DevOps Days London):
- Automating the PR workflow - the biggest complexity was in automating the part where a pull request is created when the infrastructure state changes (like in the event of auto-scaling) and then also merged automatically. Since machines and humans are collaborating on the same repository, frequent PR merges can be a frustrating experience for humans. Race conditions in merging PRs can lead to unnecessary rebasing. More importantly, it is probably not so straightforward to guarantee that the commits in the Git history reflect the exact order of the infrastructure state change events because race conditions can happen in backfilling the Git repository with infrastructure state changes triggered by the infrastructure itself.
- Complications of CI - if you are running additional checks and verification (like tests or validations), the above problem gets more complex because the exact duration of CI runs is not deterministic, making race conditions in a super fast-changing system (due to automated PRs) highly likely.
- well-tuned - The Git history is also not left of much use anyway with a ton of commits to sync infrastructure state. When I say "a ton of commits" due to infrastructure state sync or reaction to an infrastructure state change event, that's not a random assumption for argument. I actually mean it. In a well-tuned infrastructure with thoughtfully designed auto-scaling policies, auto-scaling will happen many many times throughout the day to keep infrastructure costs in vary as the demand of the system varies, and that's okay! But then replicating those infrastructure changes in the Git repo makes the Git repo less useful to humans.
Given such complexities, we started evaluating our objectives all over again and realised that it is pointless to put the entire infrastructure state, especially the state that changes due to external conditions, in a Git repository because we follow GitOps. That's not the point of GitOps, not in my opinion anyway.
The point of GitOps is to enable practices like CI/CD for infrastructure development and infrastructure configuration management and enable seamless collaboration among humans.
Configuration vs State?
I have mentioned infrastructure configuration vs state several times. To be on the same page, let's get the definitions right for the scope of this article.
What's Infrastructure Configuration?
Infrastructure Configuration is a declarative way to specify in code how you want your infrastructure to finally end up i.e. state.
For example, Kubernetes manifests are a type of configuration. A Kubernetes deployment manifest specifies how the infrastructure for running an application should be provisioned and how much of it should be provisioned (i.e. pod replicas). A Kubernetes HPA manifest specifies how the infrastructure should scale up or down on the basis of rules. It does not specify the exact number of pod replicas at a given point.
What's Infrastructure State?
Infrastructure State is the final state of the infrastructure, in compliance with how we declared the infrastructure to be i.e. Infrastructure Configuration.
So, while an HPA manifest specifies the min/max pod replica count and the rules for scaling up and down, the actual count of pods is the state of infrastructure in compliance with the HPA configuration. The same logic applies to the count of instances in an EC2 Auto-Scaling Group. The same logic applies in the case of Vertical Pod Autoscaler.
Does knowing the infrastructure state help?
If infrastructure is to be treated "as cattle and not pets", then knowing the exact infrastructure state (and this is extremely relevant in the case of stateless ephemeral infrastructure like EC2 instances, Kubernetes pods, etc.) is going against that philosophy. Even if we were to challenge that wisdom, I have yet to come across how knowing the exact state of the system can be helpful.
The state changes triggered by the infrastructure platform itself, like adding new pods, are not really modified by humans directly. So even if new pods in the cluster are synced back into the Git repository, that code is not going to be changed by any human. If we don't add the exact pods into the Git repo but just modify the replica count, that doesn't help much as well in any scenario related to changing the infrastructure configuration. If the baseline configuration is changed, Kubernetes will replace all the running pods with new pods while maintaining the replica count at that time. So we don't really need to know this while changing infrastructure configuration. While I have taken only one example, I will extrapolate that to say there isn't much need to sync infrastructure state back into the Git repo from the perspective of future configuration changes, not for managing the infrastructure and not for collaboration between developers and platform engineers.
If we were to look at syncing changes back into the repo from the perspective of debugging an ongoing issue in production, the infrastructure state can be helpful. Being able to visualise what all changed in the system overall, either because of changes caused by humans (i.e. change in code and configuration) or external factors like an increase in demand leading to an increase in the number of pods, can be extremely valuable.
For example, at a high traffic when a lot of pods get spawned, the application database could start rejecting connections because every pod starts a connection pool and beyond a certain number of running pods, the database cannot accept more connections. Now, the information about the increase in the number of pods over time while debugging such an issue could be handy in reasoning about why the database is not accepting new connections all of a sudden.
Another example is catching unexpected side effects of changes, like a change in HPA policy leading to sudden and unexpected shutdown of pods, which leads to an increase in latency and error rates. Again, when the latency and error rates spike, it would be nice to know that there was a deployment around that time but also what else happened in the infrastructure, like a sudden reduction in the number of pods. This is an important piece of information to build a view of what might have happened that led to service degradation in production.
Events matter
The knowledge of infrastructure state changing over time can be valuable in debugging problems in production. The exact infrastructure state at any time is probably not as useful because it is impossible to read through the entire infrastructure state. But the incremental change in infrastructure state and what led to that change is probably far easier to consume.
Changes in infrastructure happen due to events that are either triggered by humans or are system-triggered. A deployment triggered by a change in a Git repository (a pull request getting merged) is an event triggered due to human actions. Changes triggered by the control plane of an infrastructure as a result of an infrastructure configuration and changes in some other external conditions lead to an event (like auto-scaling as a result of an increase or decrease in traffic) triggered by the infrastructure itself. Both kinds of events are important to debugging the system when something goes wrong.
In modern Cloud and Cloud Native infrastructure, there will be a lot of events triggered by the infrastructure itself. When such changes are replicated in the Git repository as well, it will lead to a lot more changes in the Git history from the infrastructure than the engineers on the team itself. So while knowing how the infrastructure state has changed over time can be extremely valuable while resolving production issues, that much information dumped in one Git repository and accessible mostly via the repository's Git history is going to be cognitively heavy for engineers to consume and put it to use effectively. When things go bad, you don't want to be reading a Git history where most changes are from a bot about syncing state.
So all the events making their way into a Git repository does not make much sense. But all the events triggered by humans (i.e. engineers making changes) should be in a Git repository for all the earlier discussed benefits of using Git for managing changes. However, there isn't much value in replicating events triggered by the infrastructure itself. In fact, it is more harmful to the developer experience.
What's a better way to manage state and events?
What is a better way to manage infrastructure state and events if not a Git repository? The infrastructure state itself is less important for engineering teams. It is primarily important for infrastructure tooling for operations like reconciliation. So if you are using Terraform, then the Terraform State file is used and managed by the tooling in the Terraform ecosystem. If it is Kubernetes, then the state is managed in etcd. And it is okay for such a state to be there.
What about events? If events (both human-triggered and infrastructure-triggered) are helpful for debugging production issues, then what's a better way to manage them for human consumption?
While debugging issues in production, system telemetry is the first thing we look at - infrastructure metrics, application metrics, APM profiles, logs, etc. In our hypothetical (but realistic) scenario of latency and error rate spikes, the on-call engineer would first jump on the observability platform to see what's happening.
If the relevant events could be visualized along with those metrics, then that makes consuming events that led to relevant infrastructure state changes a lot more consumable. Overlay that on top of the latency and error rate spike data, it all starts to be a lot more useful, especially more than being in the change history of a Git repository.
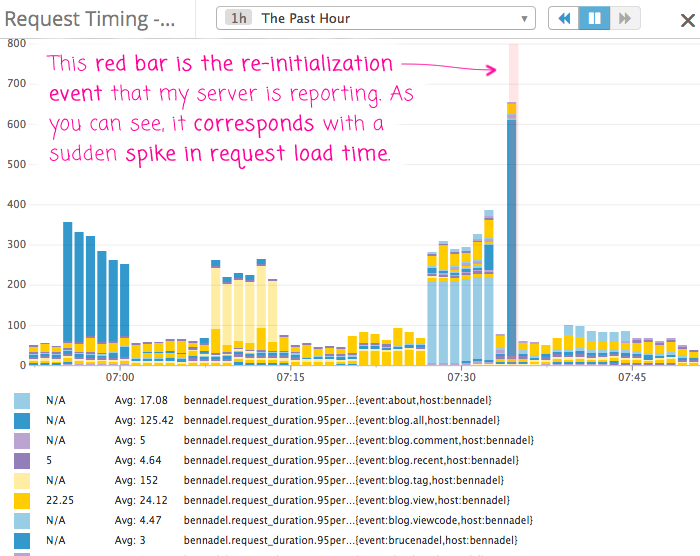
The screenshot above from a post on BenNadel.com does justice to the point I am trying to explain. The chart above is used to visualize the Request Load Time metric of the server. The light red vertical bar is an event when the server re-initialized itself, leading to a sudden spike in request load time. If this happens over and over again, a pattern can be established, and the next steps can be taken to reduce gracefully re-initialize the server without affective the Request Load Time metric.
Conclusion
Most Observability vendors have some kind of support for Events. Datadog supports it by the name Events. Grafana calls the feature Annotations. NewRelic calls it Events. Chronoshphere calls it Events as well.
This makes managing and consuming events (and infrastructure state) a lot more realistic according to practical use cases. The complexity of replicating the infrastructure state in a Git repository is not worth it. It does not improve the user experience in any way, just makes it worse. However, co-locating events with telemetry data on your observability platform makes them more usable and valuable.
This is how I have settled my thinking around infrastructure changes, state changes and events, and deriving maximum value out of them. What's your strategy to manage infrastructure changes and state changes?