Managing key-values in Consul using ConsulKV CRD
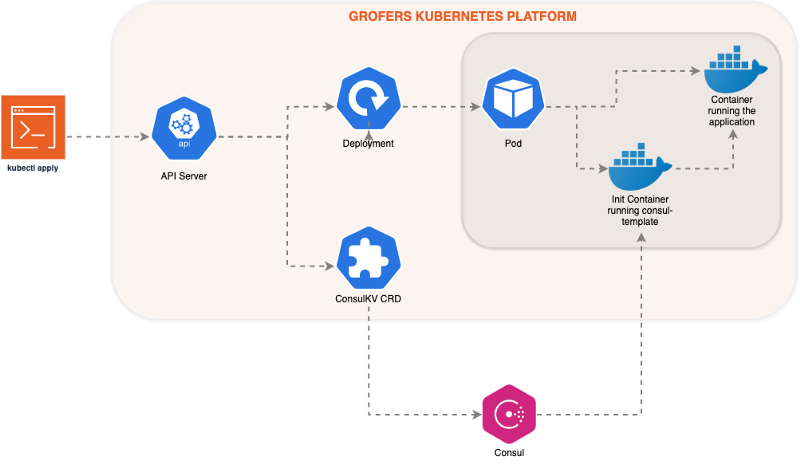
We have been deploying applications on Kubernetes for over two years. We mostly followed a lift-and-shift approach while migrating to Kubernetes. We looked for everything that Ansible used to do for us and tried to replicate it in Kubernetes. At first, everything seemed to work. But over time we realized that a simple lift-and-shift approach can complicate things over time and perhaps adopting a more Kubernetes native approach from the beginning can be better to avoid rework later. We will talk about one such challenge in this blog post — our Consul KV based approach to configuration management over using ConfigMap.
We have been often asked if we write our own CRDs, operators and controllers. We also attempt to demonstrate how we use these patterns in this blog.
ConfigMaps might not be enough for your needs
In our legacy Ansible based setup, our playbooks would orchestrate the following high-level tasks on an EC2 instance to deploy an application:
- Pull the source code or the artifact/binary
- Generate configuration file using Ansible template. Configuration was managed using host and group vars in Ansible. Secrets managed in Hashicorp Vault and pulled at runtime by Ansible. This enabled a clean way of managing environment specific configuration and secrets without repetition.
- Start the application’s process
Everything was committed in Git repositories. We liked this way of working.
The most common answer to configuration management in the Kubernetes community is using ConfigMap and Secret and storing all configuration using environment variables. We explored this approach and it would have made a lot of sense if we were starting from scratch. But it’s hard to get legacy applications to follow all the modern practices. For us, migrating from configuration files to environment variables for all the complex configurations would have been a costly migration.
The cost of migration aside, an important workflow that we feel is missing in the ConfigMap and Secret approach is the ability to reload pods when a ConfigMap or a Secret is updated along with rotation of secrets completely missing as a feature.
Consul for Configuration Management
We started looking at other options that helped us reduce the complexity and the cost of migration. In our configuration management setup on Kubernetes, we wanted to follow similar high-level semantics as we did in our Ansible setup:
- Keep configuration files templated using some kind of templating language
- Keep environment configuration committed in code as well and repeat the configuration code as little as possible.
Since we already had Consul in our stack, we decided to use:
- consul-template for templating configuration files
- Consul’s KV feature for storing configuration that consul-template would use while rendering templates.
- To keep Consul’s key-values in git, we decided to use git2consul.
This worked well initially. However over time, it started adding complications in our developer workflows and CI pipelines. The issues were rooted in the entire deployment workflow, in that it was not declarative any more. It was these two steps at a high-level:
- Run git2consul to sync key-values in git to Consul. This would involve additional logic for environment specific handling.
- Run kubectl apply to apply the manifests
Specific challenges in this approach were:
- Lack of support for namespacing in git2consul. This made provisioning new on-demand non-production environments hard. Conflicts were inevitable as namespacing could not be enforced.
- Git2consul has an unintuitive execution model. You have to tell git2consul the git repository where the key-values are committed. Git2consul then clones it and syncs the key-values to Consul. This is unnecessarily slow, especially for developers as they already have their git repositories cloned. We ran git2consul in the background to parallelize and speed up. But then we started seeing typical async workflow related issues (debugging was hard, observing for completion was even harder, etc.).
- To avoid conflicts to an extent (and we couldn’t go beyond a certain extent), we had to centralize all the configuration in a repository. So while our microservices were in their own repositories, their respective configurations were centralized for coordination, making developer experience unnecessarily complicated.
- We had to hack namespacing in consul for provisioning new environments by keeping all our key-values at a key as source that will be cloned by a script while creating a new environment. This was a hacky orchestration which made our CI pipelines slow and hard to reason about. Debugging configuration management related issues was getting hard. But most importantly, developers could not test configuration changes from code as new environments were seeded in with configuration already there in Consul.
Our learning through this experience was the rush of moving applications to Kubernetes without thinking through the entire software delivery architecture made problems worse later.
Simple Reliable Workflows Using CRD
To make the development, continuous integration and deployment process consistent and easy to reason about in developer workflows and in automation, we had to make every detail of deploying an application consistent with how any other object is deployed on Kubernetes — make it declarative, idempotent, eventually consistent.
Essentially, we want our applications to be deployed with just one command: “kubectl apply .”. This as a principle is important for us to be able to rely on any other cloud-native tooling like kustomize and skaffold.
We realized that we can replicate git2consul’s functionality in a more Kubernetes-native way. We started working on a CRD and after a few iterations arrived at the following API:
This ConsulKV object will create the following key-value paths in Consul:
Where “kubernetes/” is a configurable prefix to ensure that all the keys managed by ConsulKV CRD are kept isolated from other users of Consul in our infrastructure.
What are the benefits of this:
- Simple to use — Doesn’t this look a lot like ConfigMap? The design of ConsulKV CRD was intentionally kept similar to ConfigMap to keep the developer experience as simple as possible. Developers don’t need to install anything other than kubectl. No more git2consul.
- Logical namespacing in Consul — logical namespaces in Consul are created on the basis of Kubernetes namespace and name of the object. Kubernetes namespace based namespacing is helpful for setting up the same application in multiple namespaces (say, for development or CI pipelines). Object name based namespace is helpful to ensure that two different objects in the same namespace don’t end up with conflicting keys in Consul.
- Works with cloud-native tools like Skaffold and Kustomize — for example, in Skaffold’s dev mode, developers can change key-values in ConsulKV manifests and just expect the values in Consul to be directly changed without any manual intervention, making it for a much better developer workflow. Achieving GitOps with tools like ArgoCD is now possible. Compatibility achieved by using CRDs with cloud-native tools is a great benefit that simplifies a lot of things and makes everything just work.
- Achieve DRY with kustomize — common KVs across environments don’t have to be repeated. Since it’s just another Kubernetes object, you can use kustomize to override KVs specific to those environments.
- Simpler access control for Consul — developers don’t need to write to Consul directly anymore. You can depend on access control features in Kubernetes to expose Consul to your developers in a secure way.
Of course this comes with the consideration of how to namespace actual usage of paths in your applications. There are possibly two ways you are using Consul:
- Consul client libraries in applications — in this case, you will have to make your application configurable to prefix all instances of API call to account for the Kubernetes namespace which can be passed via an environment variable.
- envconsul or consul-template — both support a “prefix” option that can be used to prefix all the paths being read with <namespace>/<consul-kv-object-name>. In the above example, it will be “grofers-namespace/grofers-dot-com”
consul-kv-crd is written in Python and built using Zalando’s kopf framework for building operators which makes it super easy for teams who speak Python to adopt a more Kubernetes way of doing operations.
The implementation itself is quite simple. And we hope to make it open-source some day.
What did we really learn?
When we started moving to Kubernetes, a lot had to be still figured out even by the community about all aspects of operating applications on production. The process was painful but taught us a lot about semantics and designing processes on Kubernetes:
- Stick to the standard way every time possible. In our case, the best thing would have been to just use ConfigMap and Secret to avoid all the complexity we encountered later. Our challenge was dealing with legacy.
- If you cannot stick to standard, then use solutions that are easy to observe and reason about. In our case, the git2consul model was just not the right solution. It was slow and there were no easy ways to speed it up. No hard feelings for git2consul, but we feel just not built for our needs (and perhaps these needs are common for other teams as well).
- Try to be as declarative as possible. Use kubectl as your tooling to do everything. Best is to use “kubectl apply” to tell the cluster the eventual state you desire and walk backwards to let applications eventually stabilize.
- If being declarative is not possible or too costly in the short term and must absolutely look at an imperative process, prioritize for speed and observability. Avoid async tasks in imperative workflows that could be hard to monitor from things happening inside Kubernetes (for example, should we wait-for git2consul to finish before attempting to start the process?).
Giving developers a single pane to manage everything
Now our configuration sits right next to all other Kubernetes manifests in our application source code repositories. Developers can work with Consul the way they work with all other objects in Kubernetes.
This is a pattern that we are trying to follow with as many developer workflows as possible. An example of this is legend, a CRD for standardized Grafana monitoring dashboards for applications deployed on Kubernetes.
What’s next?
consul-kv-crd is now being used in every new application getting deployed at grofers. While it has simplified our legacy git2consul based setup, we are excited about moving to consul-template based hot-reloading of configuration changes when KVs update in Consul and rotation of secrets using leases in Vault.
We have not open-sourced consul-kv-crd yet. We are curious to learn about what the community thinks about this approach and we would be happy to open-source it if we gather enough interest from the community.
Interested in cloud-native technologies? Did you know we are hiring?
If this kind of work interests you, apply to work with us through our careers site or feel free to directly reach out to me on LinkedIn, Twitter or just drop me an email.

Vaidik Kapoor is the VP Engineering (DevOps & Security) at Grofers.
Thanks for reading Lambda.
Say hello on Twitter or follow us on LinkedIn.
We’re hiring!
We are hiring across various roles! If you are interested in exploring working at Grofers, we’d love to hear from you. You can either apply on LinkedIn or directly reach out to the author on Twitter or LinkedIn.